

Armenian Immigration to North America through the 1930s: A Compilation of Primary Sources
Abstract
Researching Armenian genealogy presents unique challenges, in large part due to the scarcity of records in the Armenian homeland and the scattering of families who survived the Armenian Genocide. Many Armenians immigrated to North America in the latter part of the 1800s and in the early 1900s. Fortunately, for those of Armenian descent living in the US and Canada, a tremendous amount of information can be found in primary source records of these countries to help them to learn about their Armenian families. The Armenian Immigration Project explores nine different types of American primary sources related to Armenian immigrants during this time period, using an evidence-based methodology to abstract over 170,000 entries from these records and present them in a searchable, free, online database.
Background
My paternal grandfather Dikran Arslanian was born around 1883 in the village of Sergevil, located in the kaza (county) of Keghi, sanjak of Erzurum (Garin), vilayet of Erzurum, in Turkey in the Ottoman Empire. He immigrated to the US through New York (Ellis Island) in 1906. Many of the men in his family also left Turkey in the years prior to the 1915 Genocide to find work in the US, Canada and western Europe in the hopes of bettering their family’s prospects and perhaps bringing their wives and children to join them. Of the 40 or so members of our extended Arslanian family remaining in Turkey in 1915, only two boys were known to have survived the Genocide. They were rescued from refugee camps in the Middle East after the end of World War I.
Dikran remained in the US, married a woman of French-Canadian descent and settled on the Pacific coast (Washington and Oregon). He finally arrived in Fresno, California in the early 1930s. My father was one of seven children born to this couple between 1918 and 1934 – first-generation Americans of Armenian and French ancestry.


As a teenager in the early 1970s, I became interested in learning more about my father’s Armenian family. My Armenian grandfather Dikran died in 1965, and my father knew very little about the Armenian side of his family (as he had been estranged from his father for many years). Dad referred me to one of his much older Armenian first cousins—Kevork, or “Uncle George” as we called him. He was born around 1895 and came to America in 1912. I met Uncle George at some family gatherings and later wrote to him with questions about our Arslanian family. George responded immediately, and we corresponded for several years. Not only did he share a lot about our Armenian family, but he gave me the addresses of several other older close relatives, including the two boys in our family who had survived the Genocide (who were then in their 60s and 70s). I put together similar questionnaires and mailed them to the other contacts, who promptly responded. Some of them also sent old photographs. One even provided a hand-drawn sketch of their home in Sergevil. (They all lived together in an extended household after my great-grandfather Sarkis Arslanian and his brother Garabed, the family patriarchs, were killed in the massacres of 1895-1896.)
The information I obtained from my correspondence with my older relatives in the 1970s enabled me to piece together our family story, but left a number of questions unanswered. In these days before the internet, widespread availability of primary source records and DNA technology, I figured that was as far as I was going to get in understanding the history of my Armenian family. At least I was able to meet some of my extended Arslanian family living in the US, England and France.
Primary Sources
Over the next several decades, I started researching primary sources to augment the information I had already learned about my Armenian family. Primary sources are official documents created near the time of the event for governmental, religious or commercial purposes, as well as unofficial material (such as correspondence or missing persons ads) created by someone with first-hand knowledge of certain facts. My research started with the general availability of the 1910 federal census, which was released to the public (via microfilm) in 1982, after a legal waiting period of 72 years. My Armenian grandfather and several of his family and fellow villagers first appeared in that census.
In addition to censuses, primary sources include vital records (births, marriages and deaths), military records (World War I and World War II draft registrations), ship manifests, citizenship records (naturalization and passport applications) and newspapers (especially missing persons ads). In those days, some of the records were available from the US and state and local governments in the form of microfilm, microfiche and paper files. Other records could be found in county courthouses and archives. During my business and personal travel in the 1980s and 1990s, I often set aside a day or two for genealogical research in courthouses, archives and cemeteries or for meeting and interviewing relatives.
The commercial availability of the internet in the 1990s was a game-changer for genealogists. Not only did forums emerge that allowed researchers to collaborate, but all kinds of different primary records started to become available online. For my Armenian research, the most important of these were the collections of ship manifests, starting with the Ellis Island website around the year 2000. I was able to take my Armenian research notes from the early 1970s and locate many of the individuals on the original ship manifests. Not only did these records reveal the relatives or acquaintances they were joining in America, but they listed (for arrivals in 1907 and later) the names and relationships of the ones they were leaving in the ‘old country.’ Many of the names of family and friends were previously unknown to me, leading to more research possibilities (new information on my Armenian family, at last!)
I became interested in learning more about other Armenian immigrants to America who originated in my grandfather’s home kaza of Keghi and eventually compiled a spreadsheet of over 2,500 immigrants from Keghi who entered America through Ellis Island. (Some were related to my Arslanian family, but I eventually learned that Keghi was quite a large kaza, consisting of over 50 Armenian villages clustered around the principal town of the kaza, called Keghi Kasaba.) To learn more about these Keghi immigrants to America, I tried to see if I could find them in the US and Canada federal census records and military draft registrations (and created spreadsheets for those).
At some point, I realized the significance of this approach for anyone researching their Armenian family who immigrated to America. I decided to expand my research beyond Keghi to include anyone of Armenian ancestry, regardless of their place of origin. More records became available online – ship manifests for ports other than Ellis Island, censuses for later years, citizenship records, vital records, newspapers, etc. (I created many more spreadsheets.)
Linkage of Primary Sources
It soon became apparent to me that there was tremendous value to be gained by looking at a number of different primary sources when researching individuals and family groups. You get a much more complete picture of a person’s history by combining information in a holistic fashion from different primary sources and timeframes, much more than you find in just a single record:
- date and place of birth (including town/village)
- interrelationships of individuals (relatives, neighbors from villages/towns in the “Old Country” and in America)
- dates and places of marriage(s) and death
- where they lived and how they got from one place to another
- occupation(s)
- how they lived and what they did
- photographs
In the 1970s, I learned that by sending the same questionnaire to different older family members, their answers didn’t always agree. Dates were problematic. (Didn’t people know their own birthdays or that of their relatives?) Sometimes the chronology of events and names of people were inconsistent. The same thing, I realized, applied when looking at primary source records. They often don’t agree. Dates are off. Place names and personal names are spelled dozens of different ways. This is the nature of research with primary sources. Rarely will all of the information in a particular record be entirely correct. Often, it will conflict with a family’s oral traditions (memories being flawed, as well). Research of any kind is messy. You can’t take anything verbatim. It is important to look at the entirety of a person’s “paper trail” of primary records to look for corroboration and discrepancies and make a judgment as to which information is likely to be correct, which is incorrect and what information you may never know.
Why are primary records not entirely accurate? Here are some of the possible explanations.
- Informant didn’t know
- Error in transcribing between work document and official document (or copying of official document)
- Lack of understanding between clerk and informant due to language difference
- Change of place names, borders; no clarity regarding level of place to use in the administrative hierarchy (e.g., village/town, kaza, sanjak, vilayet)
- Delay in time between event and recording of information
- Deliberate falsification (informant or clerk)
In general, information in a primary source is usually quite accurate with respect to things happening at the time of the record, assuming that the informant was knowledgeable. For example, a death certificate is usually correct for things like the decedent’s name, address, occupation, date and place of death, cause of death, and place of burial (or removal). That same death certificate may not be accurate for things like the decedent’s date and place of birth and names of the parents, since those things may not have been known first-hand to the informant, especially if the decedent was elderly.
Another good reason for gathering information from as many primary sources as possible for an individual is to uncover that “gem.” Many times I have gathered information for a person across many different types of primary sources, and one (and only one) of those sources contained a piece of information that allowed me to break through a “brick wall” and solve a puzzle that had perplexed family researchers for years. Perhaps there was an aunt living in the household in the 1930 census whose identity finally enabled me to identify that person’s parents. Or maybe the village of the person’s birth is only shown in the World War II draft registration (all other records for that individual giving just the name of the kaza, sanjak, vilayet or country).
After gathering information on Armenian immigrants to North America (US and Canada) from many different types of primary sources, tens of thousands of rows in multiple spreadsheets, I was challenged with how best to present this information to a global audience. At first, I just created pdf files of the spreadsheets and published them on a web server. This was not satisfactory for a number of reasons. The amount of information couldn’t easily fit on a single sheet (even in landscape mode). Each different sort order required its own spreadsheet, and it was almost impossible to link together all of the information for an individual across all of the different primary source records.
Around 2015, I solved many of these problems by organizing information from these different primary sources into tables within a database, and then publishing that database along with easy-to-use search tools to quickly view the information (over 170,000 entries) in a variety of different ways, even a consolidated view for an individual (linking all of that person’s records together).
Evidence-based Methodology
Many of the purported genealogies published in books and online are nothing more than a repetition of someone else’s mistakes due to shoddy or inadequate research. Early on, I tried to carefully document primary sources to support each relationship or event (birth, marriage or death) in my own family genealogies. Even if the primary sources are conflicting, as they often are, someone years later could at least examine each of the cited sources to draw their own conclusions.
In my research of Armenian immigrants to America (the Armenian Immigration Project), I have not attempted to document genealogies of any of the families other than my own. Rather, I am more interested in providing them with original evidence and clues that they can use to construct their own family trees or gain a better understanding of their own family histories. My role is more like an archaeologist digging up bones and artifacts, and then displaying, categorizing, cataloguing and indexing my finds. My objective is to allow others to find new information about the subjects of their research.
By gathering as much evidence from primary source material for an individual (and their close connections), researchers will be able to determine which facts are independently corroborated and which ones conflict, and then use their informed judgment to develop a narrative of their family history. Many of us are uncomfortable with uncertainty. We need to learn to accept that some level of uncertainty is unavoidable.
Oftentimes, information from primary sources will be in direct conflict with an oral family tradition that has been repeated (and probably embellished) for decades. Admittedly, it is sometimes hard to let go of these oral traditions. But that is usually the case with historical research.
Structure of Armenian Immigration Project Website
The project web site consists of two pages: Home and Project Reports and Queries.
The Home page is a description of the project – its background and each of the nine primary sources. For each primary source, a link is provided to allow you to download the entire database table in .csv format. You may import this file into your own spreadsheet program or database to create your own reports or do your own analysis. The character set is utf-8, and the column separator is a semicolon.
The Project Reports & Queries page is the workhorse of the project, allowing you to search through the more than 170,000 entries contained within the database tables. A report is a summary of data in a table (e.g., top joining street addresses on ship manifests). A query allows you to use various search criteria to find individual entries (abstracts) of the primary sources. Within the abstracts, you will often find links to other abstracts relating to the same individual or to someone in that person’s network (a relative, friend, or associate). This linkage of the abstracts is the key analytical benefit of the project.
In most cases, the abstracts do not provide a linkage to the actual image of the primary source record. There are several reasons why I chose not to do this. These include the time it would take to clip a discrete image and point to it, the fact that some types of records (like ship manifests and marriage registers) don’t lend themselves to just clipping the entry of interest without getting the whole large page with headings, the issue with links to the sources themselves (on sites like Ancestry.com or FamilySearch.org) becoming outdated and invalid, as well as possible issues with intellectual property rights. For the Ads table, I present images of missing persons ads. For some of the records in the Deaths table, I include an obituary or news item relating to the person’s death. Published content, like American newspapers, are in the public domain after 75 years. Also, Fair Use guidelines allow their selective use for this type of scholarly research.
Project Reports & Queries Page
The Project Reports & Queries page allows you to search through any of the nine database tables corresponding to primary sources, as well as a combined search (across all tables at once).
At the top is a sampling of five individual photographs. These photographs are part of a collection of over 4,000 photographs of Armenian immigrants whose entries are in the project. When you refresh the webpage, five more randomly chosen photographs will appear. If you click on a photograph, it will take you to that person’s entry. Presenting these faces is a way to help the data (names, dates and places) come alive.
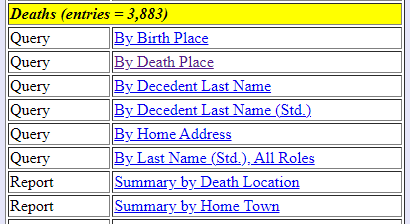
Each section on this page (delineated by headers with a yellow background) corresponds to one of the primary sources in the database. For example, you can run a query or report for the Deaths table, which includes abstracts of death registers and certificates. There are currently 3,883 entries in the table. To run the query or report, click the hot link. There are several different ways to search each table.
Let’s turn to the concept of roles. Each type of primary source record may mention one or more individuals. For example, in the death records, you will find the deceased person, his/her spouse and the parents of the deceased.

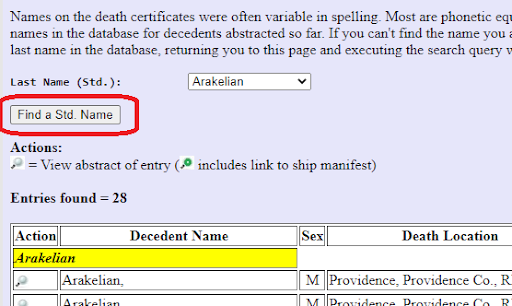
Next, how do we deal with all of the different spelling variations of personal names? For most last names, we will often find dozens of different spellings in the primary sources. Here is a sampling of those found for the last name Կրճիկեան. The transliteration of a name to the Latin alphabet is different for Western Armenian versus Eastern Armenian. It can also differ depending on where the record was written (by a French-speaking clerk preparing a ship manifest for a voyage from Le Havre or a military draft registrar in Fresno writing down a phonetic approximation of the name using American English conventions). When abstracting the names from the primary sources (those written in the Latin alphabet), I transcribed them exactly as written, so you can search across all of the different spelling variations.

To make it easier to find a last name across all of the different spelling variations, names that are phonetically similar have been grouped together under a label called the Last Name (Std.). The variations of the name Կրճիկեան can be found under the Last Name (Std.) of Grjigian. The labels are usually the Western Armenian transliteration in a style you will typically find in the US. This is not to say that this is the correct spelling of the transliterated name, as different families (or branches of the same family) may have their own spelling preferences. Sometimes, different last names may be grouped together if their spelling variations are hard to distinguish from one another or if they are based on the same root (e.g., Hagopian and Yacoubian). If a last name has commonly been anglicized to its American English equivalent (e.g., Arslanian to Lion or Lyons), you will find it grouped with the original Armenian name.
On each of the Query pages, you will find a button for a utility that maps any last name in the database to its standardized last name.
Place names are another challenge. In the Ottoman Empire, many towns and villages had different Armenian names than Turkish names, such as Garin/Erzurum, Dikranagerd/Diyarbekir, Kharpert/Harput, or Paghesh/Bitlis. Even the Turkish names were spelled differently in western European and American publications of that time (e.g., Erzurum vs. Erzeroum). After the formation of the Republic of Turkey following the end of World War I, many of the names were changed further (e.g., Smyrna to Izmir, Constantinople to Istanbul and Harput to Elazig). Of course, any place name could be found spelled dozens of different ways that are rough phonetic approximations on primary sources in American records. The same applies to names of places in the former Russian Empire (Alexandropol to Leninakan to Gyumri), now the Republic of Armenia.
For place names, the Armenian Immigration Project uses the names in place at the start of World War I (in 1914), using the style most commonly found on American maps and in English-language publications. When referring to places in Turkey, the administrative hierarchy of place names in use at that time is used. For example, my paternal grandfather’s village of birth is referred to as Keghi (Sergevil), Erzurum, Turkey, using the kaza (Keghi), followed by the town/village name in parentheses, then the vilayet (province), then the country. For places that were then in the Russian Empire (now the Republic of Armenia), the towns and villages in the okrug of Kars are grouped together, as are those in the uyezd of Alexandropol. (Kars was recaptured by the Turks and incorporated back into Turkey in 1921.)
Example of Consolidated View with Linkages
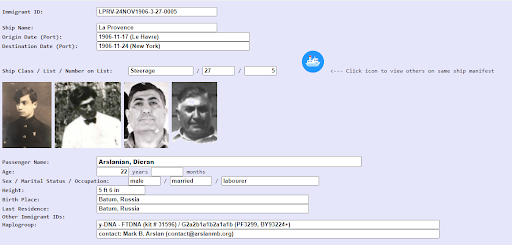
One of my key objectives for this project is to show a consolidated view of information from primary source records for individual immigrants to America. This can be illustrated with the view for my paternal grandfather Dikran “Dick” Arslanian:
The consolidated view is built around the immigrant’s ship manifest (or border crossing entry, in the event that the person arrived in the US by land through Canada or Mexico). Dikran arrived in America through New York (Ellis Island) on November 24, 1906 aboard the ship La Provence, which departed the port of Le Havre, France on November 17, 1906 (a voyage of seven days). He had traveled from his home village in Turkey to the Black Sea port of Batum (then in Russia), which was listed as his Last Residence. From there, he eventually reached France to begin the final leg of his journey to the US. Dikran, like many Armenian immigrants to America, traveled with others from his home village. To see others on his voyage, click the little ship icon. (This will bring up an additional view of voyages for that year, positioned with that particular voyage at the top of the screen. Give it about 10 seconds or so to refresh the screen for heavy immigration years like 1913 and 1921.)
The immigrant’s place of birth first appeared in the ship manifests of late 1906. As seen in Dikran’s entry, it was erroneously listed as Batum. (This is typical with many of the 1906 ship manifests, conflating the places of birth and last residence; records of 1907 and later are generally more accurate in this respect.)
Many immigrants to America, particularly men, traveled back and forth multiple times. Dikran did not. Were this the case, you would see one or more Other Immigrant IDs listed, with hot links that enable you to view abstracts of those ship manifests, as well.
If an individual’s direct male descendant had a Y-chromosome DNA test performed (typically through the Armenian DNA Project at FamilyTreeDNA), his results and a contact name would be listed here. This can be used, in Dikran’s case, to determine if other Arslanians are of the same family as him. (Most are not, unless they were from the same village in Keghi.) To be of the same family, their y-DNA results would need to be virtually identical. This field could also display the mitochondrial DNA (mtDNA) results for female immigrants. Here are the current haplogroup results for the Armenian Immigration Project database. This is a relatively new feature, which I hope will be used broadly by descendants of Armenian immigrants in America to find other members of their families.
Starting with ship manifests (to the US) in 1907, a column appeared for “The name and complete address of nearest relative or friend in country whence alien came.” In my database, I refer to this as the Leaving role (with Name, Relationship, Immigrant ID and Location). This field often contains the name of a spouse or parent in the Old Country who may or may not have come to America. (In Dikran’s case, this field is blank, since he traveled in 1906.)
Starting in about the year 1900, ship manifest entries showed the name, relationship, and street address of the person in America (“relative or friend”) they were joining (i.e., the Joining role in my database). In Dikran’s case, he was joining his older brother Marouke Arslanian in Madison, Illinois (near Granite City). By clicking on the hot link for Marouke’s Joining Immigrant ID, you can view all the information I have found for Marouke (whose photo appears above the Joining section of this page).
In the Comments field, there’s more additional information found for the immigrant on the ship manifest entry, such as if they were deported or had distinguishing physical characteristics (deformities, scars, tattoos, blue eyes, etc.).
The most important feature of this consolidated view are linkages to other entries appearing in my database for that same individual from the different types of primary sources records, which appear in the bottom section of this page. To the left of each entry, you will find a small icon depicting a magnifying glass. Clicking this icon will bring you to a view of an abstract for that record, which may itself contain linkages to other entries. For example, you will find entries for Dikran in the 1910, 1920 and 1930 census, the World War I draft registration, a naturalization application from 1920, his 1912 and 1918 marriages (the latter one to my grandmother) and his 1965 death certificate from Modesto, California.
Note that his birth date is inconsistent from entry to entry, which is typical for Armenian immigrants to America. Also, there are a number of different spellings for his first and last names.
Every few months, I refresh the online version of the Armenian Immigration Project database with new entries. This consolidated view will automatically incorporate additional entries for the immigrant with each refresh.
Conclusion
Doing an exhaustive search for your relatives in primary documentary sources takes a lot of time and patience, but it can be very rewarding and gratifying. You may find a personal signature or even a photograph that you’ve never seen before (in naturalization applications starting in 1930 and passport applications starting in 1915). Ship manifests may reveal new names and connections, as well as show how your relatives got to America. The decennial censuses of the US and Canada often show extended family groupings soon after they arrived. Be prepared for surprises, as family anecdotes are almost never completely accurate. Keep an open mind and have fun.




Mark, thank you for all that you have done. This is an incredible and an enormous gift to the Armenian people.
Thank you for all of your hard work compiling this info – I have spent years piecing together as much data as I can about my great grandparents history and I was able to make significant progress thanks to your database.
Not sure if I am able to leave requests, but I have a few photos circa 1900-1915 that have handwritten notes on the back – but they are in Armenian. Is there a good place to share this to help get translation? They also include photos from outside the family, it almost seems like it was a women’s rotary club type organization. Figure it can’t hurt to ask, thanks so much again :)
Thanks for your kind words, Stephanie. I suggest that you join the Armenian Genealogy group on Facebook and post high quality images of the photos and the notes on the back. Members of our group are very helpful in translating those.
My uncle Lt. Billy Vincent was a “Tatiosian “Tattiosian His mom was Teran Tatiosian. He was a WW2 hero and arminian. I want arminians to know about him and the town he saved in France. You can look him up on Google. The french town has a big monument and on Aug . 13th each year they honor him and what he did. He is a true Arminian hero Thank you John Lindsley You can please share this
My goodness Mark! What a job and quite a HERO you are to many of us struggling to find our ancestors. It is an adventure for sure, to search all you have put together. I am now trying to link you as an Arslan to my husband’s Uncle Jack Melkonian’s wife Evelyn Arslan b.1920. He was b.1921 Chelsea MA d.1968 LA CA. His father Misak Melkonian (b.1884 Armenia d.1960 SF CA) and wife Rose (Emerzian) (b.1892 d.1943 SF CA) and their family left MA to Fresno, then most went to SF CA, Jack & Evelyn went to LA CA. Evelyn’s father was Elijah M. Arslan b.1870 and mother Margaret Yoosef b.1886. Her father Garabed Charles Yousuf b.1849, mother Maritza Ilbegian b.1860. Maritza’s sister Amarila Anna b.1863 married Hovagim Arslan b.1850. Their 2 sons Thomas Hovagim Arslan b.1885 and Harry Arslan (b.1899 d.1972 SF CA) who were quite involved with our Melkonian family, mainly in Fresno, then SF CA. Harry worked at Thomas’ farm in Fresno, at some point married Loretta T. (MNU) and they lived in SF CA, he worked and lived with our Melkonian families at several places in SF CA. So perhaps, Uncle Harry is connected somehow to your Arlsan family! I have 32k people in My Heritage right now, and the Armenian trees/branches are growing quickly thanks to your hard work! Thank you again, Linda
Your efforts for all of us has brought great happiness to our families. WE ARE ARMENIAN, now and forever! We all thank you for bringing our ancestors to light. My husband passed away this last two weeks, and I am looking forward to having the time to revisit the site. I see the Melkonian or Nersesian names and my heart skips a beat! God bless you!
Dear Mr. Arslan:
My husband, Robert Riggs, Professor and Chair Emeritus of Music at University of Mississippi, and I were friends and colleagues of the late Ed Avadesian of MA. I also have very old Armenian genealogy —the Kings of Armenia and East Roman Emperors, through my mother’s royal European heritage. I noticed your comments on Shaver/ Schaeffer ancestry at another site. I descend from Johann Nicholas Schaeffer through his daughter Anna Barbara Schaeffer Steininger.
Hello Mark.
I was pleased to find your Armenian Immigration Project some years back. Now I am unable to find it anywhere online. My grandparents and their extended families (Dertadian, Tookmanian) came here from various places after WWI. A cousin is here from Boston and I was telling her about it. Now we are unable to look up anything. Your research is invaluable and I appreciate it so much. How can I find this information?
Thank you so much.